Покупка участка в СНТ. Что нужно знать? — LandPerm на vc.ru
Если вы задумываетесь о приобретении земельного участка в СНТ, стоит немного разобраться что такое СНТ. Зачастую в СНТ покупают землю те, кто планирует заниматься садоводством. Построить на таком участке дом и прописаться в нём тоже можно, но в этом вопросе есть некоторые нюансы.
622 просмотров
Что такое СНТ?
Аббревиатура СНТ расшифровывается следующим образом — садовое некоммерческое товарищество. Некоммерческая организация, созданная садоводами для решения общих вопросов: благоустройство территории, вывоз мусора, водоснабжение, электричество, содержание охраны и т. д.
Юридические особенности
СНТ не получает прибыль от своей деятельности. В СНТ входят собственники садовых участков, выращивающие овощи, фрукты и ягоды для собственных нужд. У СНТ есть собственный устав, который утверждается на общем собрании.
Устав должен содержать следующие пункты:
- Порядок выбора председателя СНТ;
- График собраний и форму уведомлений о них;
- Ответственность за нарушение общих правил, принятых членами СНТ;
- Другие нюансы.


Устав не должен противоречить действующим законам.
Читайте также: «ИЖС, ЛПХ, ДНП, СНТ. Что лучше выбрать?»
Что можно построить в СНТ
На участке в СНТ можно построить дачный или жилой дом, баню, хозяйственные строения.
Условия:
- Помещения нельзя использовать для коммерческой деятельности;
- Под застройку не используется более 30% площади;
- Сооружение не превышают высоту более 20 метров;
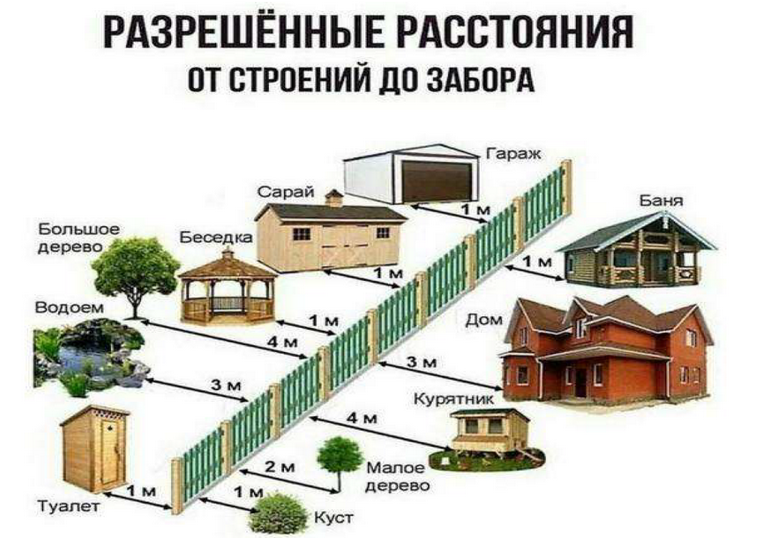
- Обязательное соблюдение правил соседства относительно заборов: 5 метров от проезжей части, минимум 1 м от забора соседей. Также забор не должен превышать 1,5 метра в высоту, что бы не создавать тень на соседнем участке.
Органы управления и их обязанности
Управлять СНТ может любой член товарищества. Главное условие, чтобы большинство собственников проголосовало именно за него. Голосование бывает открытым или тайным. Состав правления включает не менее семи человек — владельцев дач в данном СНТ.
Состав правления включает не менее семи человек — владельцев дач в данном СНТ.
В органы управления входят:
- Коллективное собрание членов товарищества;
- Председатель СНТ;
- Правление — коллегиальное звено;
- Ревизионная комиссия.
Члены правления занимают должность в течение 5 лет и после могут переизбраться повторно.
Если вы хотите приобрести земельный участок в СНТ стоит рассмотреть данный вариант. Земельный участок находится в СНТ Солнечная поляна. Площадь участка 10,9 соток. На участке есть: дом, летняя кухня, туалет, баня, теплицы. Посмотреть участок можно на нашем сайте
В обязанности СНТ входит:
- Защищать и предоставлять интересы всех членов товарищества;
- Оплачивать налоги и сборы в установленный срок;
- Содержать земельную собственность без ущерба окружающей среде;
- Своевременно подавать отчетные документы, уведомления об изменениях в составе руководящих органов;
- Ответственно относиться к общему имуществу СНТ.

Члены СНТ регулярно и в полном объёме оплачивают членские взносы, участвуют в собраниях товарищества, исполняют принятые решения.
Собрание в СНТ
За два месяца до собрания нужно провести заседание правление СНТ, на котором будет утверждаться повестка собрания. О дате, времени и месте общего собрания членов товарищества должны оповестить не позднее, чем за 2 недели до мероприятия. Оповестить могут разными способами: через СМИ, на стенде при въезде на территорию СНТ или на сайте организации.
Для принятия решения требуется кворум. Документ по результатам собрания публикуется в течение недели. Раз в год проводят собрание по утверждению бюджета, суммы взносов и решению других вопросов. Все остальные сборы — по решению правления.
Взносы в СНТ. Куда расходуются?
Членские взносы направляются на:
- Содержание общего имущества;
- Оплату ресурсоснабжающим компаниям;
- Оплату вывоза отходов;
- Работы по благоустройству территорий;
- Охрану СНТ;
- Зарплату работникам СНТ;
- Уплату налогов и сборов;
Целевые деньги идут на планирование территории, кадастровые работы, приобретение имущества для общего пользования, иные цели. Решение о расходах принимается на собрании СНТ.
Как купить участок?
Порядок покупки земельного надела в СНТ такой же, как и других объектов недвижимости. Удостоверьтесь в наличии у продавца права собственности на землю, кадастрового паспорта, справки об отсутствии у владельца долгов перед СНТ. Если продавец действует по доверенности, документ заверяют нотариально. Проверьте состояние участка и его соответствие документам.
Не покупайте землю в СНТ по садовой книжке. Такую сделку можно оспорить.
Выбрать земельный участок на LandPerm
Как перевести СНТ в ИЖС
Для перевода СНТ в ИЖС участок площадью не менее 5 соток нужно поставить на кадастровый учёт с установлением границ. Далее в правилах землепользования и застройки уточните название территориальной зоны участка. От него зависит способ перевода.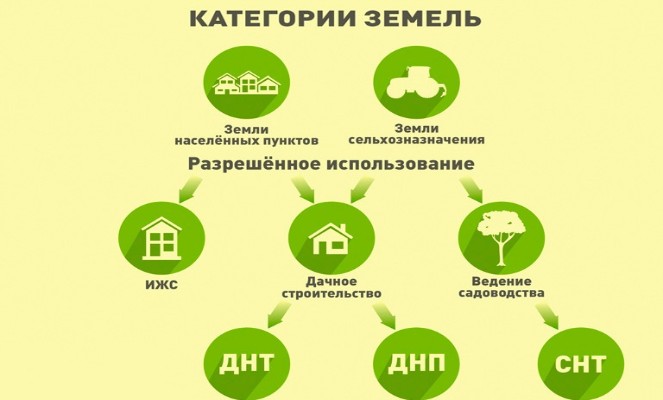
Получите выписку из информационной системы обеспечения градостроительной деятельности. Если в ней ИЖС отмечено в качестве основного вида разрешённого использования, подайте документы в МФЦ для его изменения.
При указании в правилах землепользования ИЖС в виде условно разрешённого варианта использования земли потребуется получить разрешение в местной администрации. Заявление с приложением документов рассматривается коллегиально. При отказе остаётся один вариант — оспорить решение комиссии в суде.
Плюсы и минусы
Преимущества СНТ:
- Меньшая стоимость в сравнении с ИЖС;
- Можно построить большой загородный дом;
- Участки локализуются в сельских массивах.
Недостатки покупки земли в СНТ:
- Для регистрации права на дом требуется пройти процедуру перехода из нежилой категории в жилую;
- Чаще всего в доме, построенном на садовом участке, сложно прописаться;
- Не во всех товариществах налажена уборка территорий, особенно в зимнее время года.
 Водоснабжение может работать с перебоями.
Водоснабжение может работать с перебоями.
Степень благоустройства зависит от активности и желания членов СНТ и правления.
Как перевести земельный участок из СНТ в ИЖС: правила и порядок перевода
Покупатели при выборе земельного участка для строительства жилого дома сталкиваются со многими юридическими вопросами, не понимают разницы в назначении земельных участков. Поэтому, прежде чем покупать землю, необходимо ознакомиться с некоторыми понятиями и выяснить, что такое статус и категория земель.
Определения и расшифровки аббревиатур типов земельных участков позволяют разграничить их между собой по возможностям использования, данные о которых обязательно присутствуют в генеральном плане застройки местности. Рассмотрим подробнее, что такое земли сельхозназначения и как перевести земельный участок из СНТ в ИЖС.
Содержание статьи
- Что такое участок СНТ
- Можно ли СНТ перевести в ИЖС
- Порядок перевода
- Преимущества и недостатки СНТ
- Возможные сложности
- Заключение
Что такое участок СНТ
СНТ — это садоводческое некоммерческое товарищество, являющееся юридическим лицом, в котором объединены все члены садоводства для совместного решения вопросов по благоустройству земель и управлению общим хозяйством. С 2014 года новые СНТ должны называться товариществами собственников недвижимости — ТСН.
С 2014 года новые СНТ должны называться товариществами собственников недвижимости — ТСН.
Участок СНТ — это категория земель, находящихся только на землях сельскохозяйственного назначения и предназначенных для выращивания сельскохозяйственных культур, разведения огородов.
Закон не запрещает возводить на таких участках небольшие дачные домики для сезонного проживания.
Прописаться в таком доме нельзя, но встречаются случаи, когда через суд удавалось получить разрешение на прописку. Для этого важно, чтобы жилой дом соответствовал стандартам, необходимым для комфортного проживания.
Земельные участки СНТ по стоимости являются самыми привлекательными среди других категорий земель, особенно если целью является занятие сельским хозяйством с проживанием в летнее время года. Чаще на таких участках устанавливают легко возводимые конструкции, вагончики для временного проживания.
Членом СНТ может стать любой гражданин, который купил участок, находящийся на территории товарищества. Каждый собственник получает членскую книжку товарищества, в которой фиксируются взносы, расходы на электроэнергию и другие данные.
Каждый собственник получает членскую книжку товарищества, в которой фиксируются взносы, расходы на электроэнергию и другие данные.
Несмотря на то, что садоводство создано не для коммерческих целей, существуют определенные финансовые расходы, которые возлагаются на собственников участков. Ежегодно платятся взносы на содержание садоводства.
Важно! Конкретные суммы взносов не установлены законом, размер определяется председателем и бухгалтером товарищества и зависит от количества соток земли, принадлежащих каждому участнику общества.
Совет может ввести и другие взносы на свое усмотрение, исходя из нужд товарищества: за вступление нового собственника в садоводство, на подведение воды, вывоз мусора, освещение улиц и т.д.
Каждое СНТ действует на основании устава, который составляется в процессе создания товарищества. В дальнейшем в устав вносятся изменения посредством голосования членов товарищества на общем собрании.
Можно ли СНТ перевести в ИЖС
ИЖС — это аббревиатура, введенная в Градостроительном кодексе РФ, которая обозначает назначение земель для индивидуального жилищного строительства. На землях ИЖС разрешено строить индивидуальные дома высотой до трех этажей для постоянного проживания.
Построенному объекту присваивается адрес, владелец дома и его семья без проблем могут прописаться в нем. Если планируется самостоятельное строительство на подобном участке, то собственник получает право провести все необходимые коммуникации к объекту.
Земли ИЖС, находящиеся в пределах поселений, могут иметь определенные плюсы и минусы.
Преимущества участка ИЖС:
- Прописка в собственном построенном доме.
- Участки, находящиеся в пределах поселков, могут попасть под программы администрации по благоустройству населенного пункта. Мероприятия могут включать прокладывание новых асфальтированных дорог, освещение улиц, озеленение территорий, прокладку тротуарных дорожек, проведение водопровода, подключение к электросети, газификацию.

Все эти программы финансируются из местного или регионального бюджетов, а не на средства жителей, в отличие от собственников СНТ, которые все затраты по облагораживанию территории несут сами.
Недостатки:
- Высокая цена на участок ИЖС.
- Налог на землю выше, чем на другие категории земель.
- Если 3 года на участке ИЖС не начинается строительство дома, то администрация может участок изъять.
- Если строительство не ведется в течение 10 лет, увеличивается сумма налога на землю.
Достаточно часто встречаются случаи, когда приобретаются земельные участки СНТ или ДНП (дачное некоммерческое партнерство), а собственники планируют перевести их в индивидуальную жилую собственность. Это очень сложный процесс.
Рассмотрим подробнее, как перевести землю из садоводства под ИЖС.
Перевод земель из одной категории в другую
регламентируется Федеральным законом «О переводе земель или земельных участков из одной категории в другую» от 21. 12.2004 № 172-ФЗ.
12.2004 № 172-ФЗ.Можно ли вообще перевести земли сельхозназначения под ИЖС? Да, это возможно при соблюдении некоторых условий:
- земельный участок не должен иметь ограничений на перевод в другую категорию земель;
- необходимо иметь заключение об экологическом состоянии земли;
- земля может быть переведена в категорию ИЖС на основании документов, утвержденных соответствующими органами управления, согласно землеустроительным планам.
Порядок перевода
Для изменения статуса земельного участка необходимо обратиться в отдел администрации по работе с землей или в земельную палату по месту нахождения объекта. Основанием для изменения категории участка является желание собственника, но есть
Если земельный участок разделен на доли, то необходимо предоставить в администрацию согласие от всех собственников, убедиться в отсутствии планов администрации в перспективе использовать земельный массив под сельскохозяйственные работы.
Процедура перевода участков СНТ в ИЖС:
- Необходимо подать заявление-ходатайство в органы муниципальной власти о переводе земли.
- Приложить документы (паспорт, выписку ЕГРН и другие документы по требованию администрации) и их копии.
- Решение выносится в течение одного-двух месяцев.
- Если в переводе отказано, то обязательно будет указана причина. Документ можно обжаловать в суде.
При переводе в ИЖС можно столкнуться с определенными трудностями, поскольку потребуется обязательное изменение генплана участка, а это долгая, сложная и дорогостоящая процедура.
Зачастую отказы поступают по причине удаленности земельного участка от населенного пункта. Такие ходатайства обжаловать практически невозможно.
Преимущества и недостатки СНТ
Каждая категория земель имеет свои плюсы и минусы. Достоинства и недостатки участков ИЖС мы уже рассмотрели в разделе “Можно ли перевести СНТ в ИЖС”.
Достоинства СНТ:
- Низкая цена в сравнении с землями ИЖС.
- Расположение участка в экологически чистом месте, сельской местности.
- Землю можно использовать для ведения сельского хозяйства, по закону строительство не обязательно вести.
- Для начала строительства нет необходимости создавать проект, получать разрешение.
- Небольшой налог на землю.
Недостатки СНТ:
- Собственник оплачивает самостоятельно проведение всех коммуникаций, подведение дорог, электричества, канализации и прочего.
- Низкая стоимость постройки, так как официально объект нельзя зарегистрировать.
- Невозможно прописаться, для этого требуется осуществить перевод участка в ИЖС. Зачастую вместо положительного решения о переводе выносят постановление с требованием снести незаконную постройку.
- Нельзя получить ипотеку на такой объект, использовать в качестве залога при кредитовании в банках.

- В случае если собственнику удается перевести участок СНТ в категорию ИЖС, чаще всего обустройство территории, строительство инфраструктуры, подведение коммуникаций остается на плечах собственника. Поэтому оказывается, что рядом с домом, в котором планируется постоянное проживание, отсутствуют социально значимые объекты.
- Материальную ответственность несут все собственники товарищества, поэтому в судебные инстанции и другие государственные структуры необходимо коллективное обращение.
- Если один из владельцев товарищества не оплачивает взносы, которые являются обязательными, то его долг равнозначно распределяется между остальными членами общества, которые должны его заплатить.
Возможные сложности
Самая важная проблема, которая может возникнуть и вызвать сложности в использовании участков СНТ, — это невозможность круглогодичного проживания и строительства на таком участке.
Если администрацией запланировано использовать эти земли для сельскохозяйственных работ, то перевод вообще оказывается невозможным. Остается ждать, когда поменяется статус всего земельного массива.
Остается ждать, когда поменяется статус всего земельного массива.
Для земель категории ИЖС сложность возникает в требованиях к строительству жилого объекта и его соответствии принятым стандартам. Потребуется утверждение плана застройки в администрации, получение разрешения на строительство и множество другой бумажной волокиты.
При отсутствии коммуникаций, проведенных к участку в СНТ, который собственник планирует перевести в ИЖС, будет получен отказ. Проведение электричества, водопровода, канализации будет осуществляться за личные средства инициатора перевода земельного участка. Это требует огромных затрат.
Выходом может стать поиск соседей, которые планируют такой же перевод земли и смогут принять участие в проведении коммуникаций и оплате соответствующих работ.
Внимание! Даже в такой ситуации в дальнейшем будут появляться трудности с отсутствием дорог и объектов инфраструктуры: школ, детских садов, поликлиник и прочего.

Заключение
Итак, для реализации мечты о большом загородном доме лучше использовать земельный участок, предназначенный для индивидуального жилищного строительства, так как это позволит избежать множества проблем, возникающих при официальной регистрации строения, получении прописки, подведении коммуникаций, отсутствии социально значимых объектов. Вопросы касательно строительства на землях ИЖС регулируются законом.
Земельные участки категории СНТ являются наиболее привлекательными по цене, поэтому многие приобретают их для строительства дач и загородных коттеджей. Существенным недостатком таких построек становится проблематичность в получении прописки. Однако в настоящее время и этот вопрос можно решить при определенной настойчивости.
Смотрите это видео на YouTube
SNT › Analysis
В меню SNT Analysis доступны две команды Sholl Analysis. Опция Analysis › Shuoll Analysis… предоставляет набор предопределенных фокусных точек, из которых пользователь может выбирать. Примечание для фокусных точек на основе морфологии (например, Soma , Корневой узел (узлы): первичный апикальный дендрит (дендриты) ) соответствующие теги морфологии должны быть назначены набору путей, рассматриваемых в анализе. . Чтобы выбрать фокус вручную, см. следующий раздел.
Примечание для фокусных точек на основе морфологии (например, Soma , Корневой узел (узлы): первичный апикальный дендрит (дендриты) ) соответствующие теги морфологии должны быть назначены набору путей, рассматриваемых в анализе. . Чтобы выбрать фокус вручную, см. следующий раздел.
Sholl Analysis имеет специальную страницу документации с подробным описанием параметров, графиков и показателей.
Также можно инициировать анализ Шолля для трассировки на холсте, вручную выбрав фокальную точку. Вы можете сделать это грубо, щелкнув правой кнопкой мыши рядом с узлом и выбрав Sholl Analysis at Nearest Node из контекстного меню (сочетание клавиш: ⌥ Alt + ⇧ Shift + A .
В качестве альтернативы, для точного позиционирования центр анализа:
- Наведите указатель мыши на интересующий путь. Нажмите G , чтобы активировать его.
- Нажмите ⌥ Alt + ⇧ Shift , чтобы выбрать узел на пути.

- Нажмите ⌥ Alt + ⇧ Shift + A , чтобы начать анализ.
Диалог Sholl, созданный с помощью этого подхода, немного отличается от диалога, созданного при запуске плагина Analyze › Sholl › Sholl Analysis (From Tracings)… в главном меню Fiji. Во-первых, центр анализа автоматически берется из ближайшего (или точного) узла, на который нажимает пользователь. В дополнение к морфологии и пользовательским фильтрам тегов, Фильтрация путей Раскрывающееся меню предоставляет дополнительную возможность ограничить анализ подмножеством путей, выбранных в диспетчере путей. Еще одним преимуществом является то, что холст дисплея позволяет визуально просматривать размер шага радиуса. Для этого установите флажок Preview в разделе Sampling и поэкспериментируйте с различными размерами шага.
В дополнение к графику и таблице Sholl Profile результаты анализа могут быть визуализированы в виде цветового отображения реконструкции. Чтобы раскрасить трассировку, выберите Пути с цветовой кодировкой из раскрывающегося меню Annotations и выберите Lut из раскрывающегося меню Annotations Lut перед нажатием Run Analysis . Чтобы вывести изображение Sholl, выберите 3D-просмотрщик меток изображения в раскрывающемся меню Annotations и выберите нужный LUT.
Чтобы раскрасить трассировку, выберите Пути с цветовой кодировкой из раскрывающегося меню Annotations и выберите Lut из раскрывающегося меню Annotations Lut перед нажатием Run Analysis . Чтобы вывести изображение Sholl, выберите 3D-просмотрщик меток изображения в раскрывающемся меню Annotations и выберите нужный LUT.
Чтобы провести анализ Strahler для текущего содержимого диспетчера путей, выберите команду Utilities › Strahler Analysis в главном диалоговом окне SNT. Эта команда выведет результаты анализа в виде таблицы и графика. Эти рисунки содержат морфометрическую статистику по группе путей, связанных с каждым числом Хортона-Стралера. Обратите внимание, что эта функция анализирует трассированные реконструкции. Чтобы запустить анализ Strahler на изображениях, используйте плагин Analyze › Skeleton › Strahler Analysis… в главном диалоговом окне Fiji.
Strahler Analysis (из изображений) имеет специальную страницу документации с полезной информацией.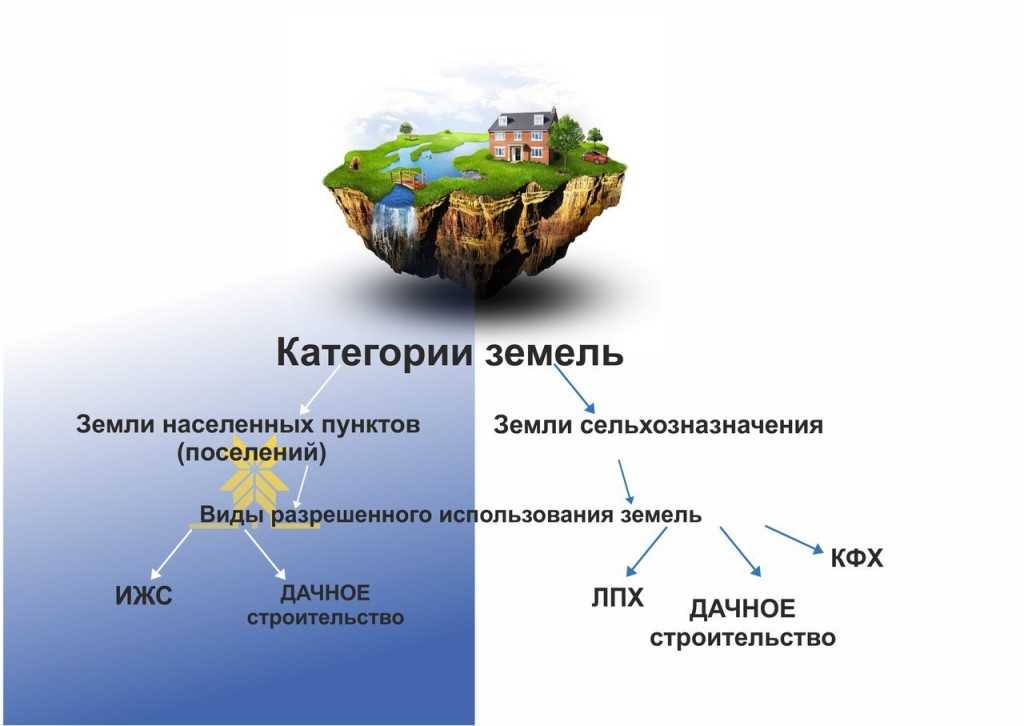
Found at Analysis › Path Order Analysis в главном диалоговом окне SNT, этот параметр анализирует пути в Path Manager на основе Path Order , в отличие от классификации Strahler, в которой классифицируются ветви (более подробную информацию об альтернативных схемах классификации ветвей можно найти можно найти, например, здесь). Создает таблицу результатов и график, аналогичный анализу Strahler 9.0004, с морфометрической статистикой по группе путей, связанных с каждым порядком ветвления.
SNT предлагает несколько способов измерения реконструкций. Полный набор измерений можно найти, перейдя в Анализ › Измерение…. в главном диалоге СНТ.
Чтобы быстро измерить все существующие пути с помощью общего набора статистических данных, выберите Анализ › Быстрые измерения. В обоих случаях результаты измерений выводятся в общую таблицу.
Чтобы получить измерения только для выбранной группы путей, сначала выберите или отфильтруйте пути, которые вы хотите измерить, в диспетчере путей, затем выберите любую команду в меню «Анализ» в диспетчере путей.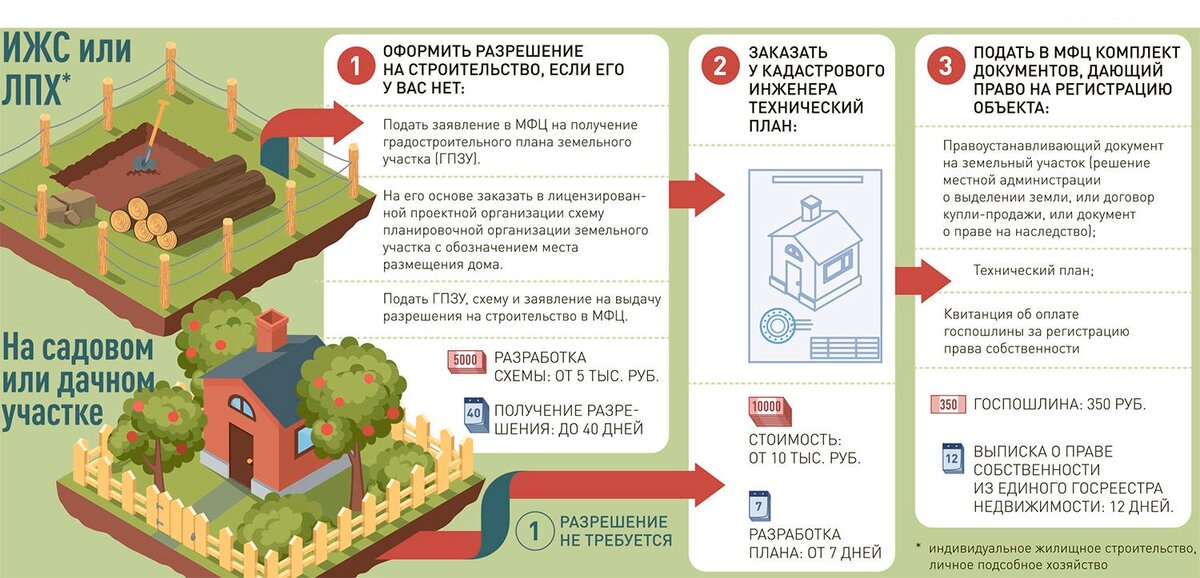
Пакетные измерения реконструкций можно выполнять с помощью сценариев. См. базовый пример Measure_Multiple_Files.py в шаблонах сценариев SNT.
Находится в Утилитах › Создать дендрограмму. Этот параметр создает дендрограмму из одного подключенного компонента (т. е. единой корневой древовидной структуры) в диспетчере путей, предоставляя высокоуровневый обзор топологии ветвления нейритов. Обратите внимание: если в диспетчере путей существует несколько корневых деревьев, вам будет предложено выбрать одно из них.
Средство просмотра предоставляет элементы управления ориентацией, уровнем масштабирования, панорамированием, редактированием вершин и обходом, а также опции для отображения меток вершин и весов ребер (которые по умолчанию являются евклидовыми расстояниями между соседними вершинами). Чтобы просмотреть доступные сочетания клавиш, щелкните правой кнопкой мыши средство просмотра и выберите Доступные сочетания клавиш… . График можно экспортировать в несколько файловых форматов, включая HTML, PNG и SVG.
Детальный программный контроль над объектами SNT Graph достигается с помощью JGraphT API в сценарии. Также актуален пакет sc.fiji.snt.analysis.graph, который предоставляет инструменты высокого уровня для создания и преобразования графиков. См. Graph_Analysis.py в шаблонах сценариев SNT для базового примера.
Команда «Утилиты» › «Сравнить реконструкции…» вызовет запрос, который дает пользователю возможность сравнить два отдельных файла реконструкции с несколькими метриками или несколько групп файлов реконструкции с одной метрикой.
Если выбрать Сравнить два файла и нажать OK , появится диалоговое окно выбора файлов, позволяющее пользователю выбрать два файла SWC и их соответствующие цвета для отображения в средстве просмотра реконструкции.
Используйте кнопку Browse , чтобы выбрать два файла, и нажмите «ОК», чтобы запустить анализ. Результаты будут включать таблицу, содержащую результаты функции Quick Measurements для обеих реконструкций, а также экземпляр средства просмотра 3D-реконструкции, отображающий обе реконструкции.
Чтобы вместо сравнения нескольких групп файлов реконструкции с одной метрикой, выберите Сравнить группы ячеек (две или более) в начальном запросе.
Запрос на выбор файла для этой опции позволяет выбрать до четырех каталогов, содержащих файлы SWC. Метрика для сравнения выбирается из раскрывающегося меню Метрика . При желании пользователь может ограничить анализ определенными отсеками нейритов. Сделав выбор, нажмите OK , чтобы запустить анализ. Результат включает в себя многопанельные фигуры, отображающие до десяти реконструкций из каждой группы, окно с метрической статистикой по каждой группе, ящичковую диаграмму и гистограмму. Все эти рисунки можно экспортировать в формате PNG или SVG.
Можно написать собственные процедуры анализа. См. Сценарии SNT для ссылки на API SNT, а также шаблоны сценариев, демонстрирующие ряд возможностей анализа.
Изучение и подготовка данных
Даны три текстовых файла, содержащие блоги, новости и твиты. Проект состоит из создания инструментов для прогнозирования текста при наборе текста на основе данных в этих файлах. Целью этого отчета о ходе работы является проведение исследовательского анализа данных, их очистка и подготовка, а также подготовка к построению прогностической модели.
Проект состоит из создания инструментов для прогнозирования текста при наборе текста на основе данных в этих файлах. Целью этого отчета о ходе работы является проведение исследовательского анализа данных, их очистка и подготовка, а также подготовка к построению прогностической модели.
Загружаем данные из трех файлов. Будем считать каждую строку во входных файлах отдельным документом.
#мы предполагаем, что каталог текущего файла является рабочим каталогом
#загружать файлы построчно, пропуская нули в твиттере, чтобы избежать предупреждений
блоги <- readLines("./data/en_US.blogs.txt", n = -1L, encoding = "en_US")
новости <- readLines("./data/en_US.news.txt", n = -1L, encoding = "en_US")
twitter <- readLines("./data/en_US.twitter.txt", n = -1L, encoding = "en_US", skipNul = TRUE) Мы подсчитываем количество строк, предложений, слов и символов в каждом файле.
#количество строк lns.blogs <- длина (блоги) lns.news <- длина(новости) lns.twitter <- длина (твиттер) #считать предложения split.snt <- strsplit(blogs, "[\\.?!]+", fixed=FALSE) #list: векторы предложений для каждой строки snt.blogs <- sum(sapply(split.snt, length)) # подсчитываем предложения каждой строки и суммируем их split.snt <- strsplit(news, "[\\.?!]+", fixed=FALSE) #то же самое snt.news <- sum(sapply(split.snt, length)) #то же самое split.snt <- strsplit(twitter, "[\\.?!]+", fixed=FALSE) snt.twitter <- сумма (sapply (split.snt, длина)) split.snt <- NULL #свободная память #счет слов split.wds <- strsplit(blogs, "[ \\.,?!]+", fixed=FALSE) #list: векторы слов для каждой строки wds.blogs <- sum(sapply(split.wds, length)) # подсчитываем количество слов в каждой строке и суммируем их split.wds <- strsplit(news, "[ \\.,?!]+", fixed=FALSE) #то же самое wds.news <- сумма(sapply(split.wds, длина)) #то же самое split.wds <- strsplit(twitter, "[ \\.,?!]+", fixed=FALSE) wds.twitter <- сумма (sapply (split.wds, длина)) split.wds <- NULL #свободная память #количество символов chr.blogs <- sum(sapply(blogs, nchar)) # подсчитываем количество символов в каждой строке и суммируем их chr.
news <- sum(sapply(news, nchar)) #то же самое chr.twitter <- sum(sapply(twitter, nchar))
Теперь мы вычисляем средние значения для трех файлов и отображаем результаты.
#среднее количество предложений в строке
spl.blogs <- snt.blogs / lns.blogs
spl.news <- snt.news / lns.news
spl.twitter <- snt.twitter / lns.twitter
# среднее количество слов в строке
wpl.blogs <- wds.blogs / lns.blogs
wpl.news <- wds.news / lns.news
wpl.twitter <- wds.twitter / lns.twitter
#среднее количество символов в строке
cpl.blogs <- chr.blogs / lns.blogs
cpl.news <- chr.news / lns.news
cpl.twitter <- chr.twitter / lns.twitter
#значительные слова в предложении
wps.blogs <- wds.blogs / snt.blogs
wps.news <- wds.news / snt.news
wps.twitter <- wds.twitter / snt.twitter
# настроить таблицу результатов
file.measur <- data.frame(
File = c("Блоги", "Новости", "Твиттер"),
Lines = c(lns.blogs, lns.news, lns.twitter),
Предложения = c(snt.blogs, snt.news, snt.twitter),
Слова = c(wds. blogs, wds.news, wds.twitter),
Символы = c(chr.blogs, chr.news, chr.twitter),
Sentences_Per_Line = c(spl.blogs, spl.news, spl.twitter),
Words_Per_Line = c(wpl.blogs, wpl.news, wpl.twitter),
Characters_Per_Line = c(cpl.blogs, cpl.news, cpl.twitter),
Words_Per_Sentence = c(wps.blogs, wps.news, wps.twitter)
)
файл.measur
blogs, wds.news, wds.twitter),
Символы = c(chr.blogs, chr.news, chr.twitter),
Sentences_Per_Line = c(spl.blogs, spl.news, spl.twitter),
Words_Per_Line = c(wpl.blogs, wpl.news, wpl.twitter),
Characters_Per_Line = c(cpl.blogs, cpl.news, cpl.twitter),
Words_Per_Sentence = c(wps.blogs, wps.news, wps.twitter)
)
файл.measur ## Строки файла Предложения Слова Символы Предложения_на_строку ## 1 Блоги 899288 2575031 37540556 208361438 2,863411 ## 2 Новости 1010242 2417242 34907255 203791400 2.392736 ## 3 Твиттер 2360148 4219494 30565160 162385035 1.787809 ## Words_Per_Line Characters_Per_Line Words_Per_Sentence ## 1 41.74475 231.6960 14.578681 ## 2 34.55336 201.7253 14.440943 ## 3 12,95053 68,8029 7,243797
Мы видим, что числа очень близки для блогов и файлов новостей , при этом блога имеют более длинные строки (с точки зрения как предложений в строке, так и слов в строке). Однако, как и ожидалось, файл twitter , хотя и меньше (меньшее количество символов) по сравнению с двумя другими, содержит более чем вдвое больше строк и вдвое меньше слов в строке.
Обратите внимание, что после сравнения приведенных выше чисел с реальными файлами мы обнаружили, что в файле en_US.news.txt в строках 77259, 766277, 926143 и 948564 есть управляющий символ, который завершает функцию readLines . Мы убрали этот символ вручную, чтобы процесс завершился правильно, чтобы читался весь файл.
Мы будем использовать n-граммы для прогнозирования ввода текста. В частности, мы будем использовать 3-граммы и 2-граммы, хотя могут быть полезны и наиболее часто встречающиеся отдельные слова.
При предсказании текста, стоп-слова как и , и т. д. играют важную роль. Мы хотели бы иметь возможность прогнозировать и их, поэтому мы не будем удалять их из обучающих данных.
Следует рассмотреть три особых случая. Первый — это цифры. Нам нужен общий способ представления числа (любого числа) в 3-граммах и 2-граммах. Полное отсутствие числа привело бы к получению n-граммы с последовательностью между предыдущим словом и следующим словом, которой на самом деле не существует. Поэтому мы решили представлять числа в n-граммах с помощью символа номер_ .
Поэтому мы решили представлять числа в n-граммах с помощью символа номер_ .
Второй случай — нежелательные слова или последовательности символов без определенного значения в английском языке. Мы проверим все термины в обучающих данных по английскому словарю, чтобы идентифицировать такие последовательности. При желании фильтрация ненормативной лексики легко реализуется путем удаления соответствующих слов из словаря (используемый словарь можно найти по адресу http://www-01.sil.org/linguistics/wordlists/english/). Последовательности символов, не совпадающие ни с одной словарной статьей, будут представлены в n-граммах символом 9.0167 noword_ . Опять же, причина того, что их не просто опускают, состоит в том, чтобы сохранить в n-граммах последовательность слов исходного текста.
Последний падеж — это конец предложения. Предсказание первого слова нового предложения должно учитывать конец предыдущего предложения, поэтому мы будем представлять конец (или, что то же самое, начало) предложений в n-граммах символом stop_ .
Наконец, для упрощения мы будем иметь дело с строчными буквами 9.Только 0004 символа, и мы не будем рассматривать как основу ни в какой части процесса.
Чтобы избежать пустой траты ресурсов, последующие процессы будут применяться и проверяться на небольшой выборке исходных данных.
ratio <- 0.002 #управляет количеством строк выборки #произвольный выбор документов (строк) set.seed(1122) blogs.idx <- as.logical(rbinom(lns.blogs, 1, отношение)) news.idx <- as.logical(rbinom(lns.news, 1, ratio)) twitter.idx <- as.logical(rbinom(lns.twitter, 1, ratio)) #создать образцы документов из исходных файлов blogs.sample <- блоги[blogs.idx] news.sample <- новости[news.idx] twitter.sample <- twitter[twitter.idx] #свободная память блоги <- NULL; новости <- NULL; твиттер <- NULL
Этот образец выбирается произвольно как доля ( отношение = 0,002) строк, содержащихся в каждом из трех файлов. Общее количество строк во всех трех исходных файлах равно 4269678, а общее количество строк трех образцов равно 8446.
Из трех образцов мы создаем объект Corpus пакета tm .
# нужны библиотеки загрузки
библиотека (НЛП)
библиотека (тм)
библиотека (RWeka)
#создаем корпус из трех образцов
образцы <- c(blogs.sample, news.sample, twitter.sample)
корпус <- корпус (VectorSource (образцы),
readerControl = список (reader = readPlain, язык = "en_US"))
#свободная память
образцы <- NULL; blogs.sample <- NULL; новости.образец <- NULL; twitter.sample <- NULL Основываясь на изложенном ранее плане, теперь мы применяем к нашему корпусу документов ряд преобразований, описанных в соответствии с кодом.
#define функция замены для корпусных документов corpus.replace <- content_transformer( #replace шаблон регулярного выражения функция(x, шаблон, замена) gsub(шаблон, замена, x, фиксированное=ЛОЖЬ) ) #порядок преобразований важен #replace - и _ с пробелом для разделения слов корпус <- tm_map(корпус, корпус.replace, "[-_]+", " ") #все символы в нижний регистр корпус <- tm_map (корпус, content_transformer (tolower)) # заменяем числа (целые, десятичные, IP-адреса, время, простые операции) на число_ корпус <- tm_map(корпус, корпус.replace, "[0-9a-zA-Z_]", "") #удалить лишние пробелы корпус <- tm_map(корпус, stripWhitespace) #заменить непонятные и нежелательные термины символом noword_ corp.docs <- sapply (корпус, контент) corp.terms <- sapply(corp.docs, strsplit, "[ ]+") термины <- "" for (idx in 1:length(corp.terms)) #конвертировать список в вектор термины <- c(terms, corp.terms[[idx]]) corp.terms <- unique(terms) #уникальные условия corp.terms <- corp.terms[ ! corp.terms==""] #удалить пустую строку corp.terms <- corp.terms[ ! corp.terms=="number_"] #удалить мета-термин number_ corp.terms <- corp.terms[ ! corp.terms=="stop_"] #удалить мета-термин stop_ num.uniq.terms <- length(corp.terms) # оставьте количество уникальных терминов, потому что это интересно dict.en <- readLines("./dict/wordsEn.txt", n = -1L, encoding = "en_US") #прочитать словарь термин <- ""; не удалось <- 0; регулярное выражение <- "" for (термин в corp.terms) { #проверить термины по словарю if ( ! is.element(term, dict.en)) { #заменить термин в корпусе неудачно <- неудачно + 1 #количество неудачных терминов regexp <- paste("[ ]+", term, "[ ]+", sep="") #соответствует ТОЛЬКО всему слову corpus <- tm_map(corpus, corpus.
replace, eval(regexp), "noword_") } } #очистка памяти dict.en <- NULL; corp.docs <- NULL; corp.terms <- NULL; термины <- NULL
Интересно отметить, что количество уникальных терминов до проверки по словарю составляет 21262, и что 5667 из них не соответствуют какой-либо словарной статье. На данный момент первые три документа в преобразованном корпусе выглядят так:
cat(' ', content(corpus[[1]]), '\n', content(corpus[[2]]), '\n ', content(corpus[[3]])) ## stop_ noword_ есть достоверные данные, что все в этой компании, особенно забастовщики noword_ подарки в компании noword_ secret santa stop_ noword_ также знают, что забастовщики посещали финансируемую компанию рождественская вечеринка, на которой они приняли участие в финансируемом компанией обеде stop_, а также noword_ ваучеры на сумму noword_ number_ от компании в качестве рождественских подарков stop_ ## stop_ пока короли и королевы кланяются и играют для вас ## стоп_ в дополнение к пособию в случае смерти полисы страхования жизни предлагают финансовую защиту страхователям и их семьям от неизлечимых хронических и критических заболеваний стоп_ используется в качестве альтернативы традиционному страхованию на случай длительного ухода Индексированные универсальные продукты страхования жизни с пособиями на проживание могут предоставлять доллары на лечение хронических заболеваний с дополнительным преимуществом в виде накопления денежной стоимости stop_ клиенты, которые отказываются платить изрядную страховую премию noword_, могут быть более чем готовы приобрести универсальный жизненный полис с индексом пособий на проживание, поскольку он может обеспечить значительную денежную стоимость, если полис будет сдан.стоп_
Теперь мы извлечем 3-граммы, которые, по сути, представляют собой набор троек последовательных терминов в корпусе. Аналогичным образом извлечем 2-грамма. Мы отсортируем их по частоте (количество раз, когда они встречаются в корпусе). Частые n-граммы могут помочь предсказать их последнее слово при вводе предыдущих.
Однако, поскольку мы использовали мета-термы number_ , stop_ и noword_ для обозначения определенных категорий терминов, нам необходимо применить некоторые правила к набору n-грамм:
- Нет смысла прогнозировать stop_ . Следовательно, n-граммы, которые заканчиваются на stop_ , бесполезны для предсказания.
- То же самое верно для number_ , поэтому n-граммы, оканчивающиеся на number_ , бесполезны для предсказания.
- n-грамм, которые имеют два последовательных stop_ , не могут быть сопоставлены и бесполезны для прогнозирования.

- n-грамм, содержащих одно или несколько noword_ , не могут быть сопоставлены и бесполезны для прогнозирования.
Триграммы
Теперь мы извлекаем 3-граммы, отсортированные по убыванию их частоты.
# создать 3 грамма
trigram.tokenizer <- function(x) NGramTokenizer(x, Weka_control(min=3, max=3))
tri.tdm <- TermDocumentMatrix(corpus, control=list(tokenize=trigram.tokenizer))
#сумма и сортировка
tri.freq <- slam::row_sums(tri.tdm)
tri.freq <- sort(tri.freq, уменьшение=ИСТИНА)
tri.total <- length(tri.freq) #общее количество 3-грамм, мера разнообразия корпуса
#удалить записи, бесполезные для предсказания
idx.del <- grepl("stop_[ ]*$", имена(tri.freq)) #rule (1)
idx.del <- idx.del | grepl("число_[ ]*$", имена(tri.freq)) #правило (2)
idx.del <- idx.del | grepl("stop_ stop_", имена(tri.freq)) #правило (3)
idx.del <- idx.del | grepl("noword_", имена(tri.freq)) #правило (4)
del.total <- sum(idx.del) #количество 3-грамм для удаления
tri. freq <- tri.freq[ ! idx.del] #удалить помеченное
#очистка памяти
tri.tdm <- NULL; idx.del<- NULL
freq <- tri.freq[ ! idx.del] #удалить помеченное
#очистка памяти
tri.tdm <- NULL; idx.del<- NULL На следующем графике показана кумулятивная частота наиболее частых 3-грамм в процентах от общего количества 3-грамм (получено 180374). Он показывает, сколько наиболее частых 3-граммов необходимо, чтобы покрыть процент изменчивости корпуса (выраженный общим количеством 3-граммов, встречающихся). Для удобочитаемости на графике показан индекс 3-граммов по оси X, а , соответствующие 3-граммам, показаны чуть ниже.
#подготовить номера для сюжета
tri.plot <- head(tri.freq, 30) #самый частый
tri.plot <- cumsum(tri.plot) #накопленная частота
tri.plot <- tri.plot * (100 / tri.total) #процент от общего числа
# заменить строки индексом для графика
tri.plot.names <- имена (tri.plot)
имена (tri.plot) <- 1: длина (tri.plot)
#участок
tri.plot.names
барплот (tri.plot, col = "военно-морской флот",
main="Суммарные частоты триграмм",
xlab="Индекс триграммы (сначала наиболее часто встречающийся)",
ylab="Частота (% от общего количества триграмм)") ## [1] "стоп_ если ты" "стоп_ спасибо за" "стоп_ было" ## [4] "много" "один из" "стоп_ это" ## [7] "стоп_ это" "стоп_ спасибо" "стоп_ в" ## [10] "из" "количество_лет" "стоп_ ты" ## [13] "спасибо за" "будет" "стоп_ есть" ## [16] "быть" "вы хотите" "остановить_мы" ## [19] "stop_ we re" "остальная часть" "часть" ## [22] "остановить_ ты можешь" "уметь" "остановить_ он был" ## [25] "стоп_ у нас" "конец" "а также" ## [28] "было" "количество_процентов" "стоп_ есть"
Биграммы
Теперь мы извлекаем 2-граммы, отсортированные по убыванию их частоты.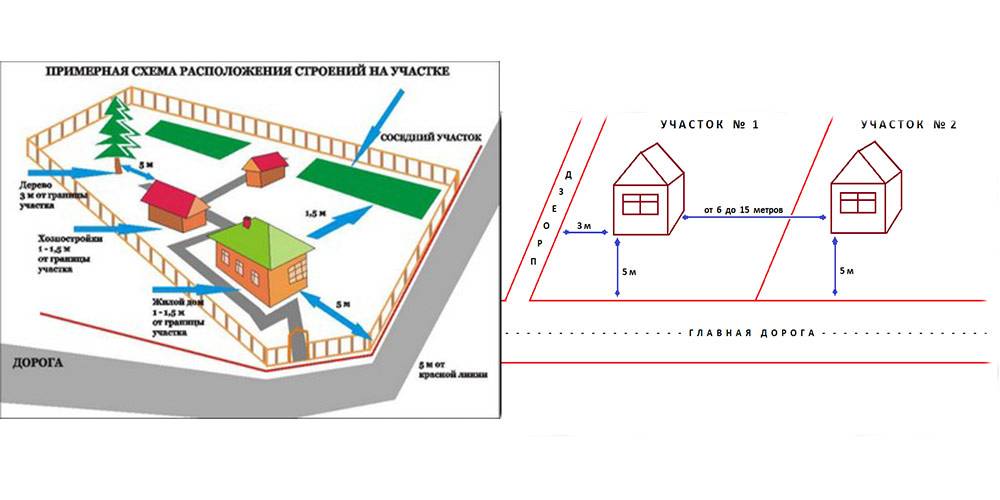
# создать 2 грамма
bigram.tokenizer <- function(x) NGramTokenizer(x, Weka_control(min=2, max=2))
bi.tdm <- TermDocumentMatrix(corpus, control=list(tokenize=bigram.tokenizer))
#сумма и сортировка
bi.freq <- slam::row_sums(bi.tdm)
bi.freq <- сортировка (bi.freq, уменьшение = TRUE)
bi.total <- length(bi.freq) #общее количество 2-грамм, мера разнообразия корпуса
#удалить записи, бесполезные для предсказания
idx.del <- grepl("stop_[ ]*$", имена(bi.freq)) #rule (1)
idx.del <- idx.del | grepl("число_[ ]*$", имена(bi.freq)) #правило (2)
idx.del <- idx.del | grepl("stop_ stop_", имена(bi.freq)) #правило (3)
idx.del <- idx.del | grepl("noword_", имена(bi.freq)) #правило (4)
del.total <- sum(idx.del) #количество 2-граммов для удаления
bi.freq <- bi.freq[ ! idx.del] #удалить помеченное
#очистка памяти
bi.tdm <- NULL; idx.del<- NULL На следующем графике показана кумулятивная частота наиболее частых 2-граммов в процентах от общего количества 2-граммов (получено 106791). Он показывает, сколько наиболее частых 2-граммов необходимо, чтобы покрыть процент изменчивости корпуса (выраженный общим количеством встреченных 2-грамм). Для удобочитаемости на графике показан индекс 2-граммов по оси X, а , соответствующие 2-граммам, показаны чуть ниже.
Он показывает, сколько наиболее частых 2-граммов необходимо, чтобы покрыть процент изменчивости корпуса (выраженный общим количеством встреченных 2-грамм). Для удобочитаемости на графике показан индекс 2-граммов по оси X, а , соответствующие 2-граммам, показаны чуть ниже.
#подготовить номера для сюжета
bi.plot <- head(bi.freq, 30) #самый частый
bi.plot <- cumsum(bi.plot) #накопленная частота
bi.plot <- bi.plot * (100 / bi.total) #процент от общего числа
# заменить строки индексом для графика
bi.plot.names <- имена (bi.plot)
имена (двойной сюжет) <- 1: длина (двойной сюжет)
#участок
bi.plot.names
гистограмма (bi.plot, col = "военно-морской флот",
main="Суммарные частоты биграмм",
xlab="Индекс биграмм (наиболее часто встречающийся)",
ylab="Частота (% от общего количества биграмм)") ## [1] "стоп_" "из" "в" "стоп_ это" "на" ## [6] "к" "для" "стоп_ мы" "стоп_ и" "быть" ## [11] "стоп_ но" "стоп_ он" "стоп_ ты" "на" "и" ## [16] "in a" "stop_ in" "с" "stop_ so" "stop_ that" ## [21] "стоп_ если" "если ты" "было" "является" "стоп_ а" ## [26] "of a" "stop_ this" "from the" "for a" "will be"
Наиболее часто встречающиеся слова
Теперь мы извлечем отдельные слова и отобразим наиболее часто встречающиеся.
# создать 1 грамм
gram.tokenizer <- function(x) NGramTokenizer(x, Weka_control(min=1, max=1))
tdm <- TermDocumentMatrix(corpus, control=list(tokenize=gram.tokenizer))
#сумма и сортировка
freq <- slam::row_sums(tdm)
частота <- сортировка (частота, уменьшение = ИСТИНА)
total <- length(freq) #общее количество 1-граммов, мера разнообразия корпуса
#удалить предопределенные мета-термины
idx.del <- grepl("stop_", имена(частота))
idx.del <- idx.del | grepl("число_", имена(частота))
idx.del <- idx.del | grepl("noword_", имена(частота))
частота <- частота[ ! idx.del] #удалить помеченное
#очистка памяти
тдм <- NULL; idx.del<- NULL
#отображать наиболее часто встречающиеся слова
голова(частота, 50) ## и для того, что вы с было это есть, но не ## 9573 4966 2270 2211 2132 1464 1288 1091 1034 991 973 818 ## из него все будут, а как насчет одного, как можно ## 772 741 666 664 658 622 610 607 599 598 596 595 ## ваш сказал, кто, когда больше там было, получил бы новое время ## 579 573 536 524 519 505 491 488 465 439 432 417 ## был какой-то она ее день наш хорошо, как теперь знать ## 406 405 402 398 397 394 389 379 348 342 331 322 ## наденьте их ## 320 316
Мы изучили данные, создали выборки из данных, преобразовали и упорядочили данные, а также извлекли 3 грамма, 2 грамма и наиболее часто встречающиеся слова.